Introduction
Data engineering is the process of collecting, transforming, and preparing data for storage, analysis, and consumption. It involves various techniques, tools, and technologies to build data pipelines that ensure the data is accurate, complete, and organized in a way that enables efficient analysis and decision-making. It involves integrating data from multiple sources, handling large volumes of data, ensuring data quality and integrity, and optimizing data processing performance.
The end goal of data engineering is to make data available for use by data analysts, data scientists, and other stakeholders to gain insights and drive business value.
Data engineering is essential in today’s data-driven world because it helps organizations transform raw data into valuable insights that can be used to drive business decisions. With the explosion of data from various sources, including social media, IoT devices, and sensors, there is an increasing need for organizations to efficiently manage and process large volumes of data. It plays a critical role in this process by ensuring that data is collected, stored, and processed in a way that enables efficient analysis and insights.
Effective data engineering can provide several benefits to organizations, including:
Improved decision-making: With a well-designed data engineering process, organizations can quickly access and analyze data, leading to faster and more accurate decision-making.
Increased operational efficiency: By automating data processing and ensuring data quality, organizations can reduce manual effort and errors, leading to increased efficiency.
Better customer insights: Data engineering enables organizations to collect and analyze customer data, leading to a better understanding of customer behavior and preferences, which can help drive targeted marketing and sales strategies.
Competitive advantage: Organizations that can quickly and effectively analyze data can gain a competitive advantage by identifying trends and opportunities before their competitors.
Microsoft Azure Data Engineering Solutions
Overview of various Azure services and tools for data engineering
Azure provides a wide range of services and tools for data engineering, which can be used to store, process, and analyse large volumes of data. Here is an overview of some of the key Azure services and tools for data engineering:
Azure Data Lake Storage: This is a cloud-based storage service that enables you to store and analyse large volumes of data in a cost-effective manner. It is designed to work with big data frameworks like Hadoop and Spark, and it offers features such as high throughput and low latency.
Azure Databricks: This is a fully managed data analytics service that is based on Apache Spark. It provides a collaborative environment for data engineers, data scientists, and business analysts to work together on data-driven projects. Azure Databricks also offers features such as auto scaling and integrated security.
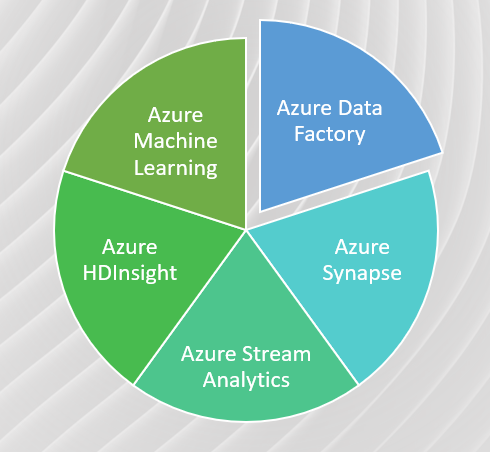
Azure Stream Analytics: This is a real-time data streaming service that enables you to process and analyse streaming data from various sources such as IoT devices, social media, and other real-time sources. It offers features such as low latency and high throughput, and it can be used to build real-time dashboards, alerts, and predictive models.
Azure HDInsight: This is a fully managed cloud-based service that enables you to process large volumes of data using popular big data frameworks such as Hadoop, Spark, and Hive. It offers features such as auto-scaling, high availability, and integrated security.
Azure Data Factory: This is a cloud-based data integration service that enables you to move data between various sources and destinations such as on-premises databases, cloud-based data stores, and SaaS applications. It offers features such as data transformation, scheduling, and monitoring.
Azure Synapse Analytics: This is an integrated analytics service that combines big data and data warehousing capabilities into a single service. It enables you to run big data and SQL analytics workloads on the same data lake, and it provides features such as data exploration, data preparation, and data warehousing.
Azure Cosmos DB: This is a globally distributed, multi-model database service that enables you to store and access data using different APIs such as SQL, MongoDB, Cassandra, and Azure Table Storage. It offers features such as low latency, high availability, and automatic scaling.
Overall, these Azure services and tools provide a powerful platform for data engineering, enabling you to store, process, and analyze large volumes of data in a scalable, cost-effective, and secure manner.
Key Features and Benefits of Azure Data Engineering
Azure Data Engineering provides several key features and benefits, including:
- Scalability makes it easy to handle large volumes of data and quickly respond to changing business needs.
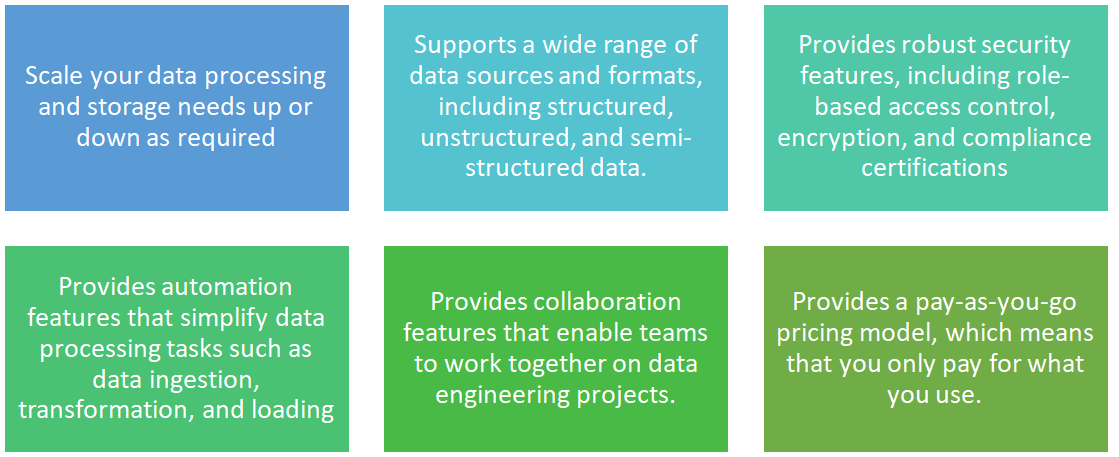
- Flexibility enables you to work with different types of data and integrate data from various sources, without having to worry about data silos.
- Security ensures that your data is secure and compliant with regulatory requirements.
- Automation reduces manual effort and enables you to focus on more value-added tasks such as data analysis and insights.
- Collaboration includes features such as version control, shared code libraries, and other collaboration tools.
- Cost effectiveness makes it a cost-effective solution for data engineering, as you don’t have to pay for unused resources.
Use Cases for Azure Data Engineering
Real-world examples of how Azure Data Engineering can be used to solve data engineering challenges
Here are some of the key use cases for Azure Data Engineering:
Data Integration and transformation:
- Azure Data Factory is a fully managed data integration service that enables organizations to ingest data from various sources, such as on-premises systems, cloud applications, and public data sources.
- The service provides a code-free visual interface to build complex data integration workflows.
Data Warehousing:
- Azure Synapse Analytics is a powerful data warehousing service that allows organizations to store and analyze large amounts of structured and unstructured data at scale.
- The service provides a unified experience to ingest, prepare, manage, and serve data for immediate business intelligence and machine learning needs.
Real-time Analytics:
- Azure Stream Analytics is a fully managed real-time data processing service that enables organizations to process and analyze streaming data from various sources in real-time.
- The service supports complex event processing and enables organizations to create real-time dashboards and alerts.
Big Data Processing:
- Azure HDInsight is a cloud-based big data processing service that enables organizations to process large amounts of data using popular big data technologies, such as Hadoop, Spark, and Hive.
- The service provides a fully managed cluster environment and integrates with other Azure services, such as Azure Data Lake Storage and Azure Blob Storage.
Machine Learning:
- Azure Machine Learning is a cloud-based machine learning service that enables organizations to build, deploy, and manage machine learning models at scale.
- The service provides a drag-and-drop visual interface for building models and supports popular programming languages, such as Python and R.
Getting Started with Azure Data Engineering
Here are the steps to get started with Azure Data Engineering:
- Create an Azure account: If you don’t have an Azure account, sign up for a free trial or create a paid account.
- Choose a Data Service: Azure offers various data services such as Azure Data Lake Storage, Azure Databricks, Azure HDInsight, and Azure Synapse Analytics. Choose the data service that best suits your needs.
- Plan your architecture: Plan your data architecture by identifying the data sources, data ingestion, data processing, data storage, and data analytics components required for your solution.
- Set up your environment: Set up your Azure environment by creating the required services, configuring permissions, and creating the necessary resources.
- Ingest Data: Ingest data from various sources using Azure Data Factory, Azure Event Hubs, or Azure Stream Analytics.
- Process Data: Process data using Azure HDInsight, Azure Databricks, or Azure Synapse Analytics.
- Store Data: Store data using Azure Data Lake Storage, Azure Blob Storage, or Azure SQL Database.
- Analyze Data: Analyze data using Azure Synapse Analytics, Power BI, or Azure Machine Learning.
- Monitor and Optimize: Monitor and optimize your data engineering solution using Azure Monitor, Azure Advisor, and Azure Log Analytics.
- Secure your solution: Secure your solution using Azure Active Directory, Azure Key Vault, or Azure Security Center.
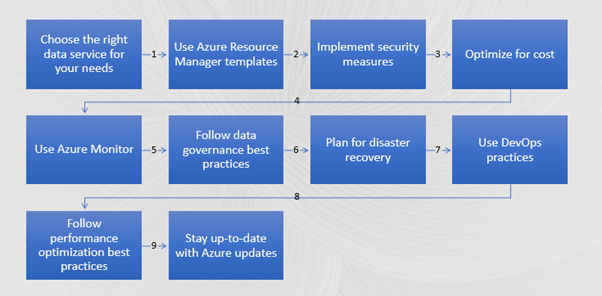
- Azure offers various data services such as Azure Data Lake Storage, Azure Databricks, Azure HDInsight, and Azure Synapse Analytics. Choose the data service that best suits your needs.
- Use Azure Resource Manager templates to deploy and manage your Azure resources. This will help you to automate the deployment and configuration of your resources and ensure consistency across your environment.
- Implement security measures such as using Azure Active Directory for authentication, Azure Key Vault for managing secrets, and Azure Security Centre for monitoring and managing security.
- Optimize your data engineering solution for cost by choosing the right size and type of resources, using auto-scaling where possible, and turning off resources when they are not in use.
- Use Azure Monitor to monitor your data engineering solution and set up alerts for critical events such as resource failures, high resource utilization, and security breaches.
- Implement data governance best practices such as data classification, data lineage tracking, and data access control.
- Plan for disaster recovery by setting up backups and replicas of your data and resources in a separate Azure region or another cloud provider.
- Use DevOps practices such as continuous integration and continuous delivery to streamline your data engineering solution deployment and management.
- Follow performance optimization best practices such as optimizing your data processing algorithms, minimizing data movement, and using caching where possible.
- Stay up to date with Azure updates and new features by reading Azure documentation, attending Azure events, and joining the Azure community.
- By following these best practices, you can create a scalable and reliable data engineering solution on Azure.
Resources for learning Azure Data Engineering:
You can learn about Azure Data Engineering through various resources and develop skills to build scalable and reliable data engineering solutions on Azure., here I have highlighted few.
- Microsoft Learn
- Azure Documentation
- Azure YouTube channel
- Azure Data Engineering blogs
- GitHub
- Udemy
- Pluralsight
Conclusion
Azure Data Engineering is a comprehensive platform that offers various services and tools for processing and managing large amounts of data effectively. It provides a scalable and flexible platform that enables modern data-driven organizations to build robust and reliable data engineering solutions.
With features such as data integration, data warehousing, big data processing, and machine learning, Azure Data Engineering can help organizations gain insights from their data and make informed decisions. By following best practices and using the available resources for learning, organizations can leverage the benefits of Azure Data Engineering to unlock the potential of their data and stay ahead in the competitive market.